
Rendering Overview
Differentiable rendering is a relatively new and exciting research area in computer vision, bridging the gap between 2D and 3D by allowing 2D image pixels to be related back to 3D properties of a scene.
For example, by rendering an image from a 3D shape predicted by a neural network, it is possible to compute a 2D loss with a reference image. Inverting the rendering step means we can relate the 2D loss from the pixels back to the 3D properties of the shape such as the positions of mesh vertices, enabling 3D shapes to be learnt without any explicit 3D supervision.
We extensively researched existing codebases for differentiable rendering and found that:
- the rendering pipeline is complex with more than 7 separate components which need to interoperate and be differentiable
- popular existing approaches [1, 2] are based on the same core implementation which bundles many of the key components into large CUDA kernels which require significant expertise to understand, and has limited scope for extensions
- existing methods either do not support batching or assume that meshes in a batch have the same number of vertices and faces
- existing projects only provide CUDA implementations so they cannot be used without GPUs
In order to experiment with different approaches, we wanted a modular implementation that is easy to use and extend, and supports heterogeneous batching. Taking inspiration from existing work [1, 2], we have created a new, modular, differentiable renderer with parallel implementations in PyTorch, C++ and CUDA, as well as comprehensive documentation and tests, with the aim of helping to further research in this field.
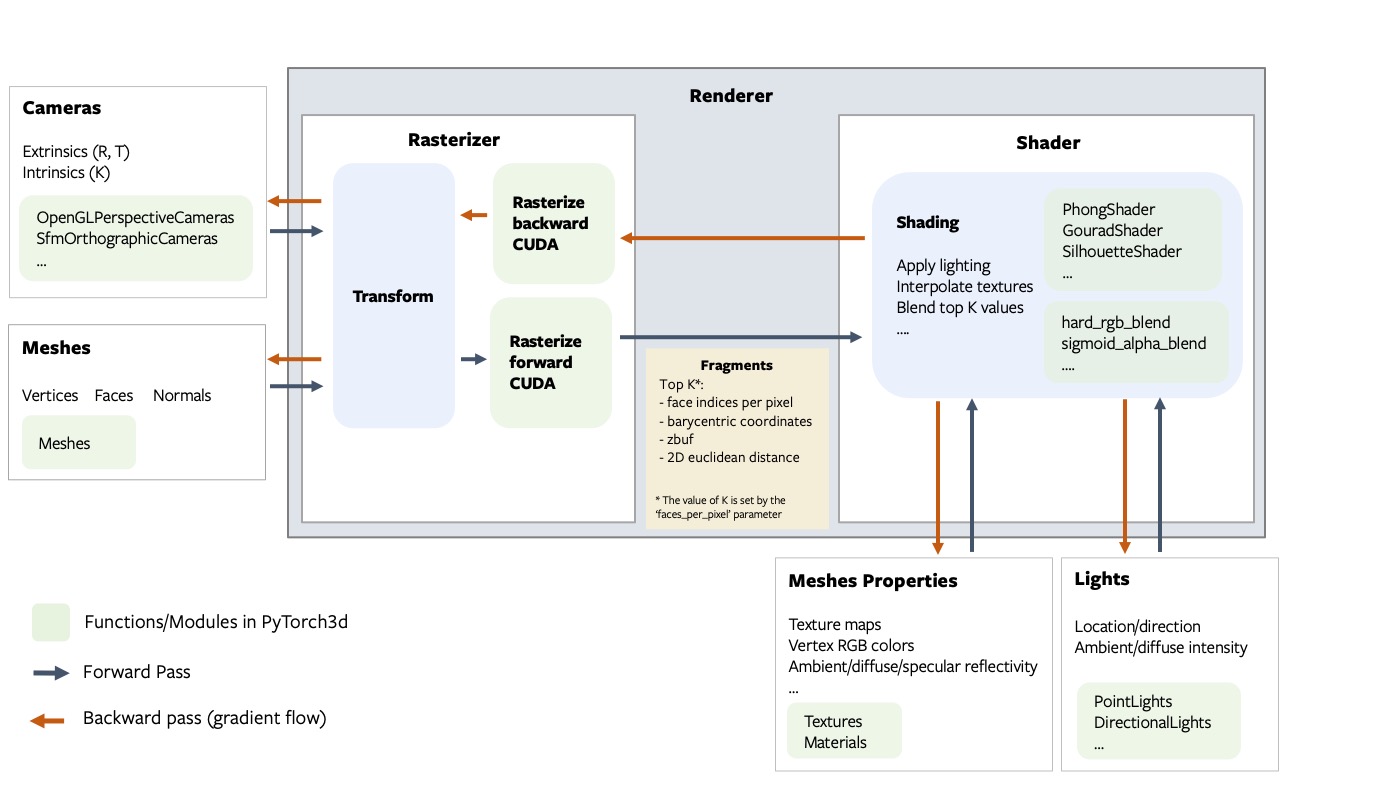
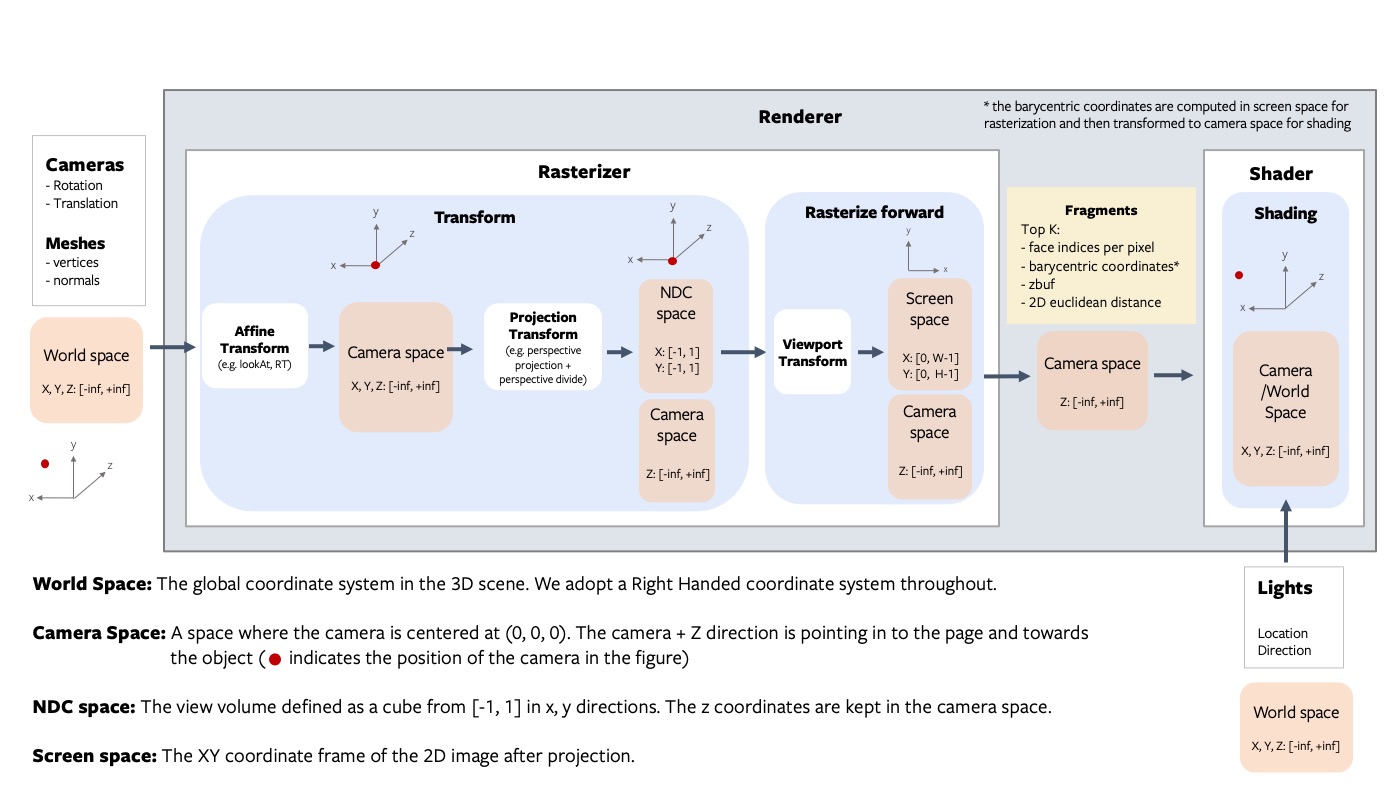
Our implementation decouples the rasterization and shading steps of rendering. The core rasterization step (based on [2]) returns several intermediate variables and has an optimized implementation in CUDA. The rest of the pipeline is implemented purely in PyTorch, and is designed to be customized and extended. With this approach, the PyTorch3D differentiable renderer can be imported as a library.
Get started
To learn about more the implementation and start using the renderer refer to getting started with renderer, which also contains the architecture overview and coordinate transformation conventions.
{kind=link}
{kind=link}
Tech Report
For an in depth explanation of the renderer design, key features and benchmarks please refer to the PyTorch3D Technical Report on ArXiv: Accelerating 3D Deep Learning with PyTorch3D, for the pulsar backend see here: Fast Differentiable Raycasting for Neural Rendering using Sphere-based Representations.
NOTE: CUDA Memory usage
The main comparison in the Technical Report is with SoftRasterizer [2]. The SoftRasterizer forward CUDA kernel only outputs one (N, H, W, 4) FloatTensor compared with the PyTorch3D rasterizer forward CUDA kernel which outputs 4 tensors:
pix_to_face, LongTensor(N, H, W, K)zbuf, FloatTensor(N, H, W, K)dist, FloatTensor(N, H, W, K)bary_coords, FloatTensor(N, H, W, K, 3)
where N = batch size, H/W are image height/width, K is the faces per pixel. The PyTorch3D backward pass returns gradients for zbuf, dist and bary_coords.
Returning intermediate variables from rasterization has an associated memory cost. We can calculate the theoretical lower bound on the memory usage for the forward and backward pass as follows:
# Assume 4 bytes per float, and 8 bytes for long
memory_forward_pass = ((N * H * W * K) * 2 + (N * H * W * K * 3)) * 4 + (N * H * W * K) * 8
memory_backward_pass = ((N * H * W * K) * 2 + (N * H * W * K * 3)) * 4
total_memory = memory_forward_pass + memory_backward_pass
= (N * H * W * K) * (5 * 4 * 2 + 8)
= (N * H * W * K) * 48
We need 48 bytes per face per pixel of the rasterized output. In order to remain within bounds for memory usage we can vary the batch size (N), image size (H/W) and faces per pixel (K). For example, for a fixed batch size, if using a larger image size, try reducing the faces per pixel.
References
[1] Kato et al, 'Neural 3D Mesh Renderer', CVPR 2018
[2] Liu et al, 'Soft Rasterizer: A Differentiable Renderer for Image-based 3D Reasoning', ICCV 2019
[3] Loper et al, 'OpenDR: An Approximate Differentiable Renderer', ECCV 2014
[4] De La Gorce et al, 'Model-based 3D Hand Pose Estimation from Monocular Video', PAMI 2011
[5] Li et al, 'Differentiable Monte Carlo Ray Tracing through Edge Sampling', SIGGRAPH Asia 2018
[6] Yifan et al, 'Differentiable Surface Splatting for Point-based Geometry Processing', SIGGRAPH Asia 2019
[7] Loubet et al, 'Reparameterizing Discontinuous Integrands for Differentiable Rendering', SIGGRAPH Asia 2019
[8] Chen et al, 'Learning to Predict 3D Objects with an Interpolation-based Differentiable Renderer', NeurIPS 2019